




Neural Computation Unit
Principal Investigator: Kenji Doya
Research Theme: Neural Computation for Flexible Learning

Abstract
The Neural Computation Unit pursues the dual goals of developing robust and flexible learning algorithms and elucidating the brain’s mechanisms for robust and flexible learning. Our specific focus is on how the brain realizes reinforcement learning, in which an agent, biological or artificial, learns novel behaviors in uncertain environments by exploration and reward feedback. We combine top-down, computational approaches and bottom-up, neurobiological approaches to achieve these goals. The major achievements of the three subgroups in this fiscal year 2010 are the following.
a) The Dynamical Systems Group is developing a new method for estimating synaptic connections in a local neural circuit from multi-electrode or optical imaging data using Bayesian inference with sparse hierarchical priors. As a part of the software development project for the next-generation super computer being built by RIKEN in Kobe, we built a spiking neuron model of the superior colliculus, which takes a pivotal role in saccadic eye movement control. We also developed a new reinforcement learning framework that can deal with long-term temporal dependencies behind high-dimensional sensory inputs like robot camera images.
b) The Systems Neurobiology Group revealed through neural recording from of three different parts of the striatum a hierarchical roles of the ventral, dorso-medial, and dorso-lateral striatum in decision making using different strategies. Through local drug injection and chemical measurement using micro dialysis, we found out that the blockade of the forebrain serotonin release impairs the ability of rats to wait for delayed rewards. We performed neural recording from rats’ lateral habenula and the ventral tegmental area to clarify the control mechanism of dorsal raphe serotonin neuron activity. We also continued analysis of functional brain imaging data to clarify the brain mechanisms for valuation of stochastic and delayed rewards and for model-free and model-based action strategies.
c) The Adaptive Systems Group has shown that a reinforcement learning method using restricted Boltzmann machine can be used for robot navigation from raw camera image and that action-oriented sensory representation is acquired in the hidden neuron layer. We also developed a new colony of quadruped robots and started behavioral learning and evolution experiments. New reinforcement learning algorithms are being developed to best utilize sensory-motor experiences and to efficiently compute optimal action policies.
1. Staff
- Dynamical Systems Group
- Dr. Junichiro Yoshimoto, Group Leader
- Aurelien Cassagnes, Technical Staff
- Dr. Makoto Otsuka, Researcehr
- Naoto Yoshida, Graduate Student
- Systems Neurobiology Group
- Dr. Makoto Ito, Group Leader
- Masato Hoshino, Guest Researcher
- Dr. Katsuhiko Miyazaki, Researcehr
- Dr. Kayoko Miyazaki, Researcher
- Alan Rodrigues, Graduate Student
- Takehiko Yoshida, Graduate Student
- Adaptive Systems Group
- Dr. Eiji Uchibe, Group Leader
- Dr. Stefan Elfwing, Researcher
- Ken Kinjo, Graduate Student
- Chris Reinke, Graduate Student
- Viktor Zhumatiy, Graduate Student
- Research Administrator / Secretary
- Emiko Asato
- Hitomi Shinzato
- Chikako Uehara
2. Collaborations
- Theme: Development of multi-scale models of visual-oculomotor system
- Type of collaboration: Joint research
- Researchers:
- Professor, Shin Ishii, Kyoto University
- Aurelien Cassagnes, Kyoto University
- Theme: Elucidation of the learning mechanism of the basal ganglia and construction of the basis for its application to next-generation robots
- Type of collaboration: Joint research
- Researchers:
- Masato Hoshino, Honda Research Institute Japan Co., Ltd
- Osamu Shono, Honda Research Institute Japan Co., Ltd
- Yohane Takeuchi, Honda Research Institute Japan Co., Ltd
- Hiroshi Tsujino, Honda Research Institute Japan Co., Ltd
- Theme: Functional brain imaging study on the brain mechanisms of behavioral learning
- Type of collaboration: Joint research
- Researchers:
- Dr. Mitsuo Kawato, ATR Computational Neuroscience Laboratories
- Dr. Erhan Oztop, ATR Computational Neuroscience Laboratories
3. Activities and Findings
3.1 Dynamical Systems Group
Sparse Bayesian identification of synaptic connectivity from multi-neuronal spike train data [Yoshimoto]
Recent progress in neuronal recording technique allows us to record spike events simultaneously from a majority of neurons in a local circuit. Such rich datasets would allow us not only to assess the information coding by neurons but also to uncover the structure of the underlying neural circuit, which is an essential step to understand the information processing mechanisms at the network level. In this fiscal year, we developed a method to identify the synaptic connections from multiple spike train data by statistical inference for a simple but general neuron model.
The method assumes that spikes are generated from stochastic leaky integrate-and-fire neurons connected with multi-exponential postsynaptic current functions. For model fitting to the data, a Bayesian parameter estimation is employed with a hierarchical prior that promotes sparseness of the effective parameters. After parameter fitting, three types of synaptic connections (excitatory, inhibitory, or none) can be identified based on the maximum amplitude of the spike response.
The performance of the method was demonstrated in synthetic benchmarks (Fig. 1). The results showed that the proposed Bayesian algorithm could achieve smaller variances of estimated model parameters compared to those by conventional maximal likelihood method. Simulation with the estimated parameters well reproduced the spike response curves. Also, the method could distinguish three types of synaptic connectivity with a high precision (Fig. 2) The explanation is in regular paragraph format.

Figure 1: (Left) A neural network from which sets of synthetic spike train data were generated in a benchmark. Gray nodes with indexes are neurons, and arrows with red-circle heads and blue-circle heads denote excitatory and inhibitory connections, respectively. (Right) A typical example of spike train data generated by this network.

Figure 2: (Left) Spike response curves reproduced by the model after the parameter fitting. The upper and bottom panels are for connections from neurons 1 to 15 and from neurons 15 to 1, respectively. The solid lines and gray areas denote averages and standard deviation over 100 independent data sets. (Right) ROC Curve to identify whether a given pair of neurons has a synaptic connection or not, which is a measure for evaluate identification performance of synaptic connectivity. The solid and dashed lines denote two parameter estimation algorithms based on maximum likelihood estimation (existing method) and sparse Bayesian estimation (our proposed method), respectively. Higher AUC score in the legend implies better identification performance.
An efficient algorithm for solving partially observable Markov decision processes with long-term dependencies [Otsuka, Yoshimoto]
While conventional reinforcement learning (RL) methods such as Q-learning can solve problems formulated as Markov decision process (MDP), many real problems do not fall into the class of MDP due to the presence of hidden states. We proposed a novel architecture for solving partially observable Markov decision process (POMDP) with long-term dependencies (Fig. 3 Left). We adopted the restricted Boltzmann machine (RBM) as a basic architecture of the reinforcement learning system. In order to handle the long-term dependencies between past observations and actions to be taken, we incorporated an echo state network (ESN), a recurrent neural network that is capable of maintaining a representation for predicting future observations and rewards. Using an image database captured in the real environment (Fig. 3 Right), we demonstrated that the proposed method successfully solved POMDPs with the long-term dependencies without any prior knowledge of the environmental hidden states and dynamics. After learning, a negative free energy of the RBM correctly approximated the optimal state-action value function (Fig. 4 Left), and task structures were implicitly represented in the distributed activation patterns of hidden nodes of the RBM (Fig. 4 Right).

Figure 3: (Left) Proposed architecture for solving POMDP with long-term dependencies. (Right) An environment with various objects, which is used for creating an image database for simulating realistic navigation task on a computer.

Figure 4: (Left) A negative free energy of the RBM in the last episode of a typical run. The dotted line denotes the expected return to go along the optimal trajectory. (Right) Activation of hidden nodes projected on the subspace spanned by the first two principal components.
Multi-scale neural modeling of visuo-oculomotor system [Cassagnes, Yoshimoto (collaborating with Morén and Shibata at NAIST)]
A challenging goal in computational neuroscience is to realize a “whole-brain” simulation linking sensory inputs to motor outputs. The visuo-oculomotor system is a good instance for approaching the goal, because the neural networks in its pathway have been well studied and mathematical models of each part have been proposed. The ultimate goal of the project is to develop a system-scale model of the mammalian oculomotor system by integrating recent knowledge from behavioral to neurophysiological level.
In this fiscal year, we developed a physiologically plausible spiking neuron-level model of the superior colliculus as part of the saccadic eye movement system (Fig. 5). Two major features of the area are the bursting behavior of its output neurons that drive eye movements, and the spreading neuron activation in the intermediate layer during a saccade. We showed that the bursting activity profile that drives the main sequence behavior of saccadic eye movements could be generated by a combination of NMDA and cholinergic synapses driven by a local circuit. We also showed how the long-range spreading activation could occur (Fig. 6), and proposed that the functional role for this mechanism is to track the general activity level and trigger a system-wide reset at the end of a saccade.
Also, we are now implementing the oculomotor control system by connecting this superior colliculus mode with brainstem integrator network and the eyeball plan models on highly parallelized computers, with help of MUSIC (Multi-Simulation Coordinator) developed by the initiative of INCF.

Figure 5: (Left) The principal components in the early saccade vision system. The retina and lateral geniculate nucleus does early vision processing; the SC and related areas integrate sensory data to generate motor commands; the brainstem systems regulate muscle activity; the cerebellum tunes the other systems over time. (Right) Block diagram of the superior colliculus model. White triangles are excitatory connections and black triangles are inhibitory. Dashed connections are external inputs. Dotted connections are not used in the current model. QV: Quasivisual; SNpr: Substantia nigra pars reticulata; cMRF: Central mesencephalic reticular formation.
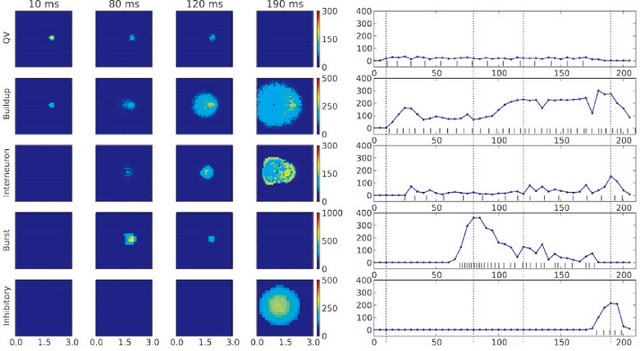
Figure 6: Intermediate SC model activity in response to a steady input. From top to bottom: Quasivisual neuron layer (QV); buildup neuron layer; inhibitory interneurons; burst neuron layer; and deep layer inhibitory neurons. Supercial SC and synthetic cMRF integrator not shown. Burst neuron layer inhibited for the first 50ms. (Left) 10ms averaged spatial activity in spikes/s of each area at 10ms (stimulus onset), 80ms (burst neuron peak), 120ms (buildup neuron spreading activity) and 190ms (deep layer inhibition). (Right) Averaged activity traces of neurons in a 300μm radius around the stimulation center, with the spike train of each center neuron at the bottom. Dotted lines mark the 10, 80, 120 and 190ms time points.
3.2 Systems Neurobiology Group
Roe of serotonin in actions for delayed rewards [Katsuhiko Miyazaki, Kayoko Miyazaki]
While serotonin is well known to be involved in a variety of psychiatric disorders including depression, schizophrenia, autism, and impulsivity, its role in the normal brain is far from clear despite abundant pharmacology and genetic studies. From the viewpoint of reinforcement learning, we earlier proposed that an important role of serotonin is to regulate the temporal discounting parameter that controls how far future outcome an animal should take into account in making a decision (Doya, Neural Netw, 2002).
In order to clarify the role of serotonin in natural behaviors, we performed rat neural recording and microdialysis measurement from the dorsal raphe nucleus, the major source of serotonergic projection to the cortex and the basal ganglia.
We found that the level of serotonin release was significantly elevated when rats performed a task working for delayed rewards compared with for immediate reward (Miyazaki et al., Eur J Neurosci, 2011). We also found that many serotonin neurons in the dorsal raphe nucleus increased firing rate while the rat stayed at the food or water dispenser in expectation of reward delivery (Miyazaki et al., J Neurosci, 2011).
To examine causal relationship between waiting behavior for delayed rewards and serotonin neural activity, we applied 5-HT1A agonist 8-OH-DPAT into the dorsal raphe nucleus which reduces serotonin neural activity through activation of auto receptors, locally by reverse dialysis method. We found that 8-OH-DPAT treatment significantly impaired waiting for long delayed reward. The result suggests that activation of dorsal raphe serotonin neurons is necessary for waiting for delayed rewards.
Neuronal coding of value-based and finite state-based decision strategies in the dorsal and ventral striatum [Ito]
Recent brain imaging and lesion studies suggest that different algorithms for decision making, such as habitual and goal-directed action selection or model-free and model-based strategies, are supported by distinct parts of the cortico-basal ganglia network. However, neuronal coding for multiple algorithms has not been reported yet.
In order to examine algorithm-specific information coding in the striatum, we recorded neuronal activities from the dorsolateral striatum (DLS), the dorsomedial striatum (DMS) and the ventral striatum (VS) of rats performing a choice task. In this task, a rat was required to perform a nose-poke to either the left or right hole after an offset of a cue tone. A reward pellet was delivered stochastically with the probabilities for left and right choices were set from four settings and varied from block to block.
We first tested fitting rat’s choice sequences to three classes of decision algorithms: reinforcement learning (RL) algorithms that update action values, environmental state estimation (ESE) algorithms that infers the probability of the reward setting in one of four possible states, and finite-state agent (FSA) algorithms in which the rat can be in one of N internal states and behaves according to state-dependent action probabilities and action- and reward-dependent state transition probabilities. Consistent with our previous study, Q-learning with forgetting effect (FQ) model showed the highest prediction accuracy among RL algorithms. The performance of ESE algorithms was worse than those of RL algorithms. With FSA algorithms, the model with 8 states showed the highest prediction accuracy and surpassed the FQ model, especially when the reward probabilities were relatively low.
We then analyzed the striatal neuronal activity. The action values estimated by FQ models were coded in neurons in DMS. The current and next states estimated by FSA model were represented in DMS and VS. These results suggest that the striatum is involved in not only value-based but also working memory-based decision strategies.

Figure 7: A finite state agent model representing rat’s choice behavior. It was assumed that a rat can be in one of eight internal states and behaves according to state-dependent action probabilities and action- and reward-dependent state transition probabilities. We estimated the transition probabilities and the action probabilities from rat’s choice behavior and found that the states form clusters which correspond to different strategies; keep left, keep right, and win-stay-lose-switch.
Multiple learning strategies in cortico-basal ganglia networks [Rodrigues, Yoshida, Ito, Yoshimoto]
We hypothesized a three-system parallel model for action selection and learning from reward and trial-and-error. When knowledge of the task dynamics is unavailable, an action-value-based method is used through gradual learning of future rewards from experience. If an internal model is available, a model-based method is implemented by mental simulation to predict future states reached by hypothetical actions. After repeated experiences, a memory-based method is employed for fast selection of actions found successful for a given sensory state. A functional MRI (fMRI) experiment was conducted to test whether and how humans use these strategies and their brain mechanisms. Subjects performed a "grid-sailing task" whose goal was to move a cursor from its start position to a goal with the shortest sequence of finger movements. Each of three different cursors was associated to a three-move direction key-mapping (KM) rule. Different KMs and start-goal (SG) positions were combined to form KM-SG sets. Subjects extensively learnt action sequences for fixed KM-SG sets in a training session. Three task conditions were performed in the fMRI experiment; condition 1: new KM with new SG, condition 2: learnt KMs with new SG, and condition 3: learnt KM-SG sets. A delay of 4~6s preceded the go signal in half of the trials. Behavior analysis revealed a variable and slow learning in condition 1, fast learning with high reward score especially after the delay in condition 2, accurate and fast execution in condition 3. The results suggest the value-based method was used in condition 1, the model-based method in condition 2, and the memory-based method in condition 3. The fMRI analysis of the delay period found that the use of value-based method in condition 1 elicited activity in the medial orbital frontal cortex and ventromedial striatum, activation in the model-based method in condition 2 was located in the dorsolateral prefrontal cortex and dorsomedial striatum, and activation by use of memory-based method in condition 3 was in the supplementary motor area and dorsolateral striatum. We showed that humans use multiple selection strategies depending on their experiences, existence of a model and time for thinking, and their realization by distinct neural networks.

Figure 8: Brain areas activated during the delay period. The medial orbitofrontal cortex (left) and ventromedial striatum (right) were active by the use of the value-based method in Condition 1(orange), whereas the use of a model-based method in Condition 2(blue) elicited activity in the dorsolateral prefrontal cortex and dorsomedial striatum.
Behavior and brain activation associated with delayed and probabilistic reward [Yoshida, Rodrigues, Ito, Yoshimoto]
The properties and neural mechanisms of decision-making under a variety of conditions, such as the delay and the stochasticity in the delivery of reward, have been studied for each of the factors. However, in real life, the outcome of a choice can be delayed and probabilistic and the choice properties and neural substrate for decisions under such situations have not been well studied. Here we performed a functional MRI experiment using primary reward and examined the subjects’ choice properties and brain activities. On each trial, subjects were required to select one of two stimuli, each associated with a different delay and probability of reward. Behavioral data and the BOLD signal were analyzed by using both hyperbolic and exponential discounting models. The regression analysis revealed that the activities in the superior and inferior parietal cortices were respectively related to the evaluation regarding the delay and the probability of reward. The analysis by the reward value with both delay and probability discounting suggested that these separate evaluations of the delay and the probability are integrated in the parietal cortex and the cingulated cortex.

Figure 9: Brain activities correlated with delay and probability specific discounting (p0.001, uncorrected extended threshold=5 voxels) and discounting by both delay and probability (p0.001, uncorrected extended threshold=0 voxels). Red: voxels correlated delay discounting. Blue: voxels correlated with probability discounting. Yellow: voxels correlated with delay and probability discounted value. Horizontal slices at z=17, 24, 33 (upper), 37, 39 and 60 (lower) from left to right.
The computational principle of flexible learning of action sequences [Hoshino]
A major challenge in applying machine learning techniques to robotic intelligence is huge uncertainty in the environment. We investigate how our brain flexibly selects the right learning algorithms and parameters for motor sequence learning without any prior knowledge of correct sequence or task constraints.
We developed a motor sequence learning task in which rats learn to press levers on the walls of an octagonal operant chamber in an unknown sequence using intracranial self-stimulation reward only after the completion of the entire sequence.
One rat could learn three-step sequence among four levers with more than 80% accuracy after 2000 episodes, during 20 hours of training. We observed non-monotonic changes in their lever press sequence features.
Correlation analysis between the motor sequences of rats and those from reinforcement learning simulations by the Q-learning algorithm with different length of memory indicated that the state variables and learning parameters changed with the progress of learning. These results suggest that rats can flexibly choose appropriate learning methods and parameters in accordance with learning progress.
We aim to develop a new modular learning framework for flexibly choosing suitable learning modules for given situations.

3.3 Adaptive Systems Group
Free-Energy Based Reinforcement Learning for Vision-Based Navigation with High-Dimensional Sensory Inputs [Elfwing, Otsuka, Uchibe]Although Reinforcement Learning (RL) has been proven to be effective for a wide variety of delayed reward problems, conventional methods cannot handle high-dimensional state spaces. One promising approach is free-energy based RL in which the action-value function is approximated as the negative free energy of a restricted Boltzmann machine. In this study, we test if it is feasible to use free-energy reinforcement learning for real robot control with raw, high-dimensional, sensory inputs through the extraction of task-relevant features in the hidden layer. We first tested, in simulation, whether free-energy based reinforcement learning can efficiently learn a vision-based navigation and battery capturing task using high-dimensional sensory inputs. We, then, tested if free-energy based reinforcement learning can be used for on-line learning in a real robot with an omnidirectional camera. Figure 11 visualizes the learned weights in the hardware experiment. The pixels that could detect the battery were along a skewed half circle, and the weights show how the restricted Boltzmann machine performed state and action abstraction by clustering state inputs that corresponded to similar actions.

Figure 11 The learned weights connecting from the state nodes to the hidden nodes, and from action nodes to hidden nodes
Reinforcement Learning for Lipschitz-discontinuous value functions [Zhumatiy, Uchibe]
In this study, a new reinforcement learning framework in which the state variable is constructed simply from the sequence of observations and the Hamilton-Jacobi-Bellman (HJB) equation over the non-Euclidian metric space is solved by a modest assumption of the local linearity of state transition. The value function for a given state is computed by nearest-neighbor approximation from previously experienced states as the node points while taking into account possible Lipschitz-discontinuity of value functions. The values on the node points are updated using the stored state trajectories by taking into account the possible problem of locally-constant functions approximation. We tested the performance of the proposed framework using non-linear learning control tasks of an inverted pendulum and a cart-pole balancer. The tasks were successfully learned without any prior knowledge in the smoothness of the value function and the analysis of the value function confirmed appropriate identification of the Lipschitz-discontinuity. The figure shows the algorithm was successfully representing Lipschitz-discontinuous regions of value function. This contrasts with previous research, where such Lipschitz-discontinuities were handled by increasing number of base nodes.

Figure 12 Update trajectories (black lines) around inverted stability point of a converged value function for a regular base grid. Colder color of circles marks higher values of corresponding base point, marked by big circles. Smaller circles correspond to intermediate steps of the extrapolating modeler.
Optimizing the parameters of central pattern generators for walking robots [Reinke, Uchibe]
The control of locomotion of legged robots by biologically inspired central pattern generators (CPGs) has turned out to be a powerful method. However, in order to generate appropriate rhythmic motions, the numerous parameters of the CPGs should be tuned. In this study, an evolutionary algorithm was used to optimize the parameters for faster movement. The optimization with the Evolution Strategy (ES) algorithm was conducted on a physical robot and its simulator (figure 13). The fitness was measured by the time taken to walk a certain distance marked by colored patches on the floor.
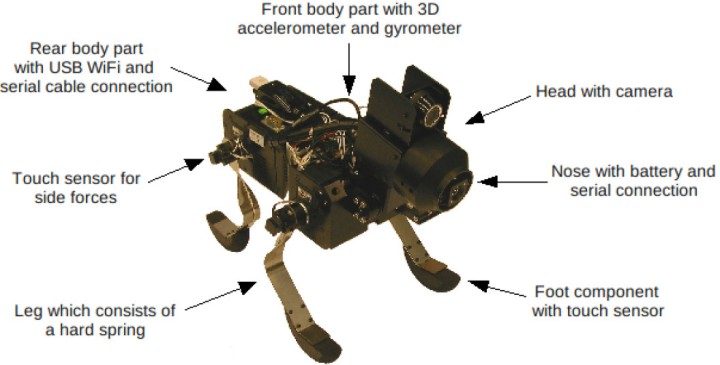
In both simulation and hardware experiments, CPG parameters could be evolved which had more than twice of the performance of the initial hand-tuned parameters. When the best parameters evolved in the simulator was applied into the physical system, we found that the mean performance was similar but the variance of the evolved parameters was higher.

Figure 14 Results of the ES optimization. (left) run on the simulator. (right) run on the physical Spring Dog. The fitness of the best and worst individual (blue) and the mean fitness for each generation with the standard deviation (red) is given.
Linear MDP with model learning [Kinjo, Uchibe]
In order to derive an optimal control law, we need to solve a nonlinear stochastic Bellman equation. However, it is difficult to find the solution analytically. To simplify this problem, Todorov proposed a technique to strictly linearize a Bellman equation with a class of cost function by exponential transformation of the variable. This enables derivation of the value function and the optimal control law by solving an eigenvalue problem. Todorov also showed that the solution of a linear Bellman equation in continuous state and time becomes en eigenfunction, which can be derived by functional approximation. Although these techniques are attractive for application to real robot, the system dynamics need to be known in advance. Therefore, we proposed a method that integrates Todorov's method with model learning. In this framework, the optimal control law is derived from the system dynamics estimated based on the sequence of states and action. We investigated the influence of the function approximation method and the modeling error on the control performance in a simulation of a task with nonlinear dynamics (swing-up pole). Figure 15 shows the exponential value function (desirability function) and the derived optimal control.

Figure 15 Desirability function and optimal control in the swing-up pole task.
4. Publications
4.1 Journals
- Elfwing, S., Uchibe, E., Doya, K., Christensen, HI. Darwinian embodied evolution of the learning ability for survival. Adaptive Behavior, doi:doi: 10.1177/1059712310397633 (2011).
- Fermin, A., Yoshida, T., Ito, M. & Yoshimoto, J. Evidence for Model-Based Action Planning in a Sequential Finger Movement Task. Journal of Motor Behavior 42, 371-379 (2010).
- Klein M, Kamp H, Palm G & Doya, K. A computational neural model of goal-directed utterance selection. Neural Networks 23, 592-606 (2010).
- Miyazaki, K., Miyazaki, K. W. & Doya, K. Activation of dorsal raphe serotonin neurons underlies waiting for delayed rewards. J Neurosci 31, 469-479, doi:31/2/469 [pii] 10.1523/JNEUROSCI.3714-10.2011 (2011).
- Miyazaki, K. W., Miyazaki, K. & Doya, K. Activation of the central serotonergic system in response to delayed but not omitted rewards. European Journal of Neuroscience 33, 153-160, doi:DOI 10.1111/j.1460-9568.2010.07480.x (2011).
- Miyazaki K. W, Miyazaki K, Doya K. Neural mechanism of impulsivity. Japanese Journal of Clinical Psychopharmacology 13, 1107-1111 (2010).
4.2 Books and other one-time publications
Nothing to report
4.3 Oral and Poster Presentations
- Cassagnes, A., Doya, K., Moren, J., Yoshimoto, J. & Shibata, T. Integration of visuo-motor network models by MUSIC, Neuroinformatics 2010, Kobe, Japan, Aug 30-Sep 1, 2010
- Doya, K. The temporal credit assignment problem and the dopamine and serotonin signaling, Inserm Lecture, Paris, France, May 10, 2010
- Doya, K. The roles of the basal ganglia and serotonin in planning ahead. , Journee Alfred Fessard Lecture, Paris, France, May 11, 2010
- Doya, K. Reinforcement learning, voluntary motor control and neuromodulation, Computational and Cognitive Neurobiology CSHL-Asia course, Suzhou, China, Jul 11-24, 2010
- Doya, K. Reinforcement learning, basal ganglia, and neuromodulation, Advanced Course in Computational Neuroscience 2010, Freiburg, Germany, Aug 2-27, 2010
- Doya, K., Fermin, A., Yoshida, T., Yoshimoto, J. & Ito, M. Model-free and model-based strategies in motor sequence learning, Workshop for Informatics on Embodiment, Onna, Okinawa, Nov 4, 2011
- Doya, K. & Ito, M. Representation of action and action values in the striatum., Janelia conference on Neural Circuits of Decision-Making, Ashburn, USA, Mar 6-9, 2011
- Elfwing, S. Mbodied evolution of learning ability and the emergence of different mating strategies in a small robot colony, Dagstuhl Seminar: Exploration and Curiosity in Robot Learning and Inference Dagstuhl, Germany, Mar 31, 2011
- Elfwing, S., Otsuka, M., Uchibe, E. & Doya, K. Free-energy based reinforcement learning for vision-based navigation with high-dimensional sensory inputs, 17th International Conference on Neural Information Processing 2010, Sidney, Australia, Nov 25, 2010
- Fermin, A., Yoshida, T., Ito, M., Yoshimoto, J. & Doya, K. Neural mechanisms for model-free and model-based reinforcement strategies in humans performing a multi-step navigation task. , Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Fermin, A., Yoshida, T., Ito, M., Yoshimoto, J. & Doya, K. Neural circuits for model-free and model-based action selection strategies in multi-step action learning, 41st NIPS International Symposium, Okazaki, Japan, Dec 16, 2010
- Fermin, A., Yoshida, T., Ito, M., Yoshimoto, J. & Doya, K. Neural mechanisms for model-free and model-based reinforcement strategies in humans performing a multi-step navigation task, International Social for Young Researchers, Neuro 2010, Kobe, Japan, Sep 2, 2010
- Funamizu, A., Ito, M., Doya, K., Kanzaki, R. & Takahashi, H. Model-free and model-based strategy for rats’action selection, Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Funamizu, A., Ito, M., Doya, K., Kanzaki, R. & Takahashi, H. Task-dependent selection of model-free and model-based strategies in rat choice behaviors., 40th Annual Meeting of the Society for Neuroscience., SanDiego, USA, Nov 17, 2010
- Hoshino, M., Tsujino, H. & Doya, K. Adaptive selection of learning method and parameters for autonomous sequence learning in rats., 40th Annual Meeting of the Society for Neuroscience, SanDiego, USA, Nov 16, 2010
- Hoshino, M., Tsujino, H. & Doya, K. Adaptive selection of learning strategy for autonomous sequence learning in rats., 17th International Conference on Neural Information Processing[ICONIP2010], Sidney, Australia, Nov 25, 2010
- Ito, M. & Doya, K. Hierarchical information coding in the striatum during decision making tasks, Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Ito, M. & Doya, K. Differential representation of action command in dorsolateral, dorsomedial, and ventral striatum in decision-making tasks., 40th Annual Meeting of the Society for Neuroscience, SanDiego, USA, Nov 14, 2010
- Ito, M. & Doya, K. Hierarchical information coding in the striatum during decision making tasks, International Social for Young Researchers, Neuro 2010, Kobe, Japan, Sep 2, 2010
- Ito, M. & Doya, K. Upcoming action encoded in the striatum during a decision-making task. Japan-German Computational Neuroscience Workshop, Japan-German Computational Neuroscience Workshop, Onna, Okinawa, Mar 5, 2011
- Ito, M. & Doya, K. Various information coded in the striatum during decision making tasks. , Janelia conference on Neural Circuits of Decision-Making, Ashburn, USA, Mar 8, 2011
- Moren, J., Shibata, T., Cassagnes, A., Yoshimoto, J. & Doya, K. Modeling saccades through NMDAR-mediated bursting with reciprocal inhibition in the Superior Colliculus, Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Moren, J., Shibata, T., Cassagnes, A., Yoshimoto, J. & Doya, K. Modeling saccades through NMDAR-mediated bursting with reciprocal inhibition in the Superior Colliculus, Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Moren, J., Shibata, T. & Doya, K. Toward a spiking neuron model of the oculomotor system, 11th International Conference on Simulation of Adaptive Behavior (SAB 2010), Paris, France, Aug 25-28, 2010
- Moren, J., Shibata, T., Yoshimoto, J. & Doya, K. A spiking-neuron model of Superior Colliculus reproduces saccade movement profiles through NMDAR-mediated burst activity, 3rd Bio Super Computing Symposium, Kobe, Japan, Feb 21-22, 2011
- Moren, J., Shibata, T., Yoshimoto, J. & Doya, K. A spiking-neuron model of superior colliculus reproduces saccade movement profiles through NMDAR-mediated burst activity, 11th Winter Workshop on the Mechanism of Brain and Mind, Hokkaido, Japan, Jan 11-13, 2011
- Nakano, T., Yoshimoto, J., Wickens, J. & Doya, K. Electrophysiological and molecular mechanisms of synaptic plasticity in the striatum, Neuro 2010, Kobe, Japan, Sep 2-4, 2010
- Nakano, T., Yoshimoto, J., Wickens, J. & Doya, K. Electrophysiological and molecular mechanisms of synaptic plasticity in the striatum: multi-scale simulation of molecule and cell, Neuroinformatics 2010, Kobe, Japan, Aug 30- Sep 1, 2010
- Nakano, T., Yoshimoto, J., Wickens, J. & Doya, K. Multi-level simulation of corticostriatal synaptic plasticity depending on input timing, 40th Annual Meeting of the Society for Neuroscience, SanDiego, USA, Nov 11-14, 2010
- Otsuka, M., Yoshimoto, J. & Doya, K. Free-energy-based reinforcement learning in a partially observable environment, European Symposium on Artificial Neural Networks (ESANN), Brugge, Belgium, Apr 30, 2010
- Otsuka, M., Yoshimoto, J. & Doya, K. Free-Energy-Based Approach to POMDPs with High-Dimensional Stochastic Observations, Japan-German Joint Workshop on Computational Neuroscience, Onna, Okinawa, Mar 3, 2011
- Uchibe, E. Finding Intrinsic Rewards by Embodied Evolution and Constrained Reinforcement Learning, Dagstuhl Seminar: Exploration and Curiosity in Robot Learning and Inference, Dagstuhl, Germany, Mar 28, 2011
- Yoshimoto, J., Inoue, T. & Doya, K. A Bayesian parameter estimation and model selection tool for molecular cascades: LetItB (Let It found by Bayes), Neuroinformatics 2010, Kobe, Japan, Aug 30-Sep 1, 2010
- Ito, M. & Doya, K. Differential representation of action command in dorsolateral, dorsomedial, and ventral striatum in decision-making task, 11th The Mechanism of Brain and Mind Summer Workshop, Sapporo, Jul 29, 2010
- Miyazaki K. W, Miyazaki K. The inhibition of serotonin neuron activity affects the waiting behavior for delayed rewards, 11th The Mechanism of Brain and Mind Winter Workshop, Hokkaido, Jan 12, 2011
- Miyazaki, K., Miyazaki, K. W. & Doya, K. Neural activity of serotonin and non-serotonin neurons during waiting for delayed rewards, 11th The Mechanism of Brain and Mind Winter Workshop, Rusutsu, Hokkaido, Jan 11-13, 2011
- Kinjo K., Uchibe E., Yoshimoto J., Doya K.. Robot Control based on linearized Bellman equation -- System identification and approximation of desirability function --, IEICE Neurocomputing Workshop, Tokyo, Mar 7, 2011
- Funamizu A., Ito M., Doya K., Kanzaki R., Takahashi H. Uncertainty of expected reward value in rat's choice behavior, 11th The Mechanism of Brain and Mind Summer Workshop, Sapporo, Jul 29, 2010
- Doya K. Basal ganglia and action value learning, Lectures commemorating retirement of Professor Minoru Kimura, Kyoto, May 22, 2010
- Doya K. Toward multi-scale brain modeling, Workshop on Neuroinformatic Basis, Tokyo, June 2, 2010
- Doya K. Basal Ganglia, Neuromodulators, Evolutionary Robotics, Kyoto University Comuptational Neuroscience Adjunct Unit, Kyoto, Sep 28, 2010
5. Intellectual Property Rights and Other Specific Achievements
Nothing to report
6. Meetings and Events
6.1 Seminar
- Date: June 17, 2010
- Venue: OIST Campus Lab1
- Speaker: Dr. Haruhiko Bito (University of Tokyo Graduate School of Medicine)
6.2 Seminar
- Date: June 30, 2010
- Venue: OIST Campus Lab1
- Speaker: Dr. Eugene Izhikevich (Brain Corporation)
6.3 Technical Group for Informatics on Embodiment (IEB)
- Date: November 4, 2010
- Venue: OIST Seaside House
- Co-organizers: The Institute of ElectronicsInformation and Communication Engineers(IEICE)
- Speakers:
- Dr. Kenji Doya (OIST)
- Dr. Jun Izawa (The University of Electro-Communicationse)
- Dr. Yoko Yamaguchi (RIKEN)
6.4 The 5th PRESTO Meeting of the Research Area (Decoding and Controlling Brain Information)
- Date: November 5-7, 2010
- Venue: OIST Seaside Hosue
- Co-organizers: Japan Science and Technology Agency (JST)
- Speakers:
- Dr. Tadashi Isa (NIPS)
- Dr. Erik De Schutter (OIST)
- Dr. Jeff Wickens (OIST)
6.5 Seminar
- Date: November 8, 2010
- Venue: OIST Campus Lab1
- Speaker: Dr. Shoji Komai (NAIST)
6.6 Seminar
- Date: November 22, 2010
- Venue: OIST Campus Lab1
- Speaker: Dr. Toshiya Matsushima (Hokkaido University)
6.7 3rd Japan-Germany Joint Workshop on Computational Neuroscience
- Date: March 3-5, 2011
- Venue: OIST Seaside House
- Co-organizers:
- Japan Science and Technology Agency (JST)
- Bundesministerium für Bildung und Forschung (Germany)
- Deutsche Forschungsgemeinschaft (Germany)
- Speakers:
- Dr. Stefan Rotter (BCCN Freiburg/University of Freiburg)
- Dr. Shigeru Shinomoto (Kyoto University)
- Dr. Michael Rosenblum (Potsdam University)
- Dr. Taro Toyoizumi (RIKEN BSI)
- Dr. Ikuko Nishikawa (Ritsumeikan University)
- Dr. Ulrich Egert (BCCN Freiburg/University of Freiburg)
- Dr. Jun-nosuke Teramae (RIKEN BSI)
- Dr. Thomas Wachtler (BCCN Munich/Ludwig-Maximilians-Universität München)
- Dr. Shin Ishii (Kyoto University)
- Dr. Gillian Queisser (University of Frankfurt)
- Dr. Hiroshi Tamura (Osaka University)
- Dr. Yoichi Miyawaki (NICT/ATR)
- Dr. Kentaro Katahira (JST ERATO)
- Dr. Helge Ritter ( Universität Bielefeld)
- Dr. Makoto Ito (OIST)
- Dr. Martin Sommer w/Michael Nitsche (Georg-August-University)
- Dr. Jeff Wickens (OIST)